Perché questo progetto
Preparavo un workshop e mi serviva esporre un url con una specifica interfaccia, risparmiando ai partecipanti di installare docker o qualsiasi altro programma nel proprio computer.
Il workshop l’ho preparato in locale con docker compose, che è uno dei metodi per sviluppare e testare in locale: funziona, è veloce, è riproducibile. E poi?
E poi ti serve spostare tutto nel cloud. E da buon developer pigro, perché non usare direttamente quel docker compose?
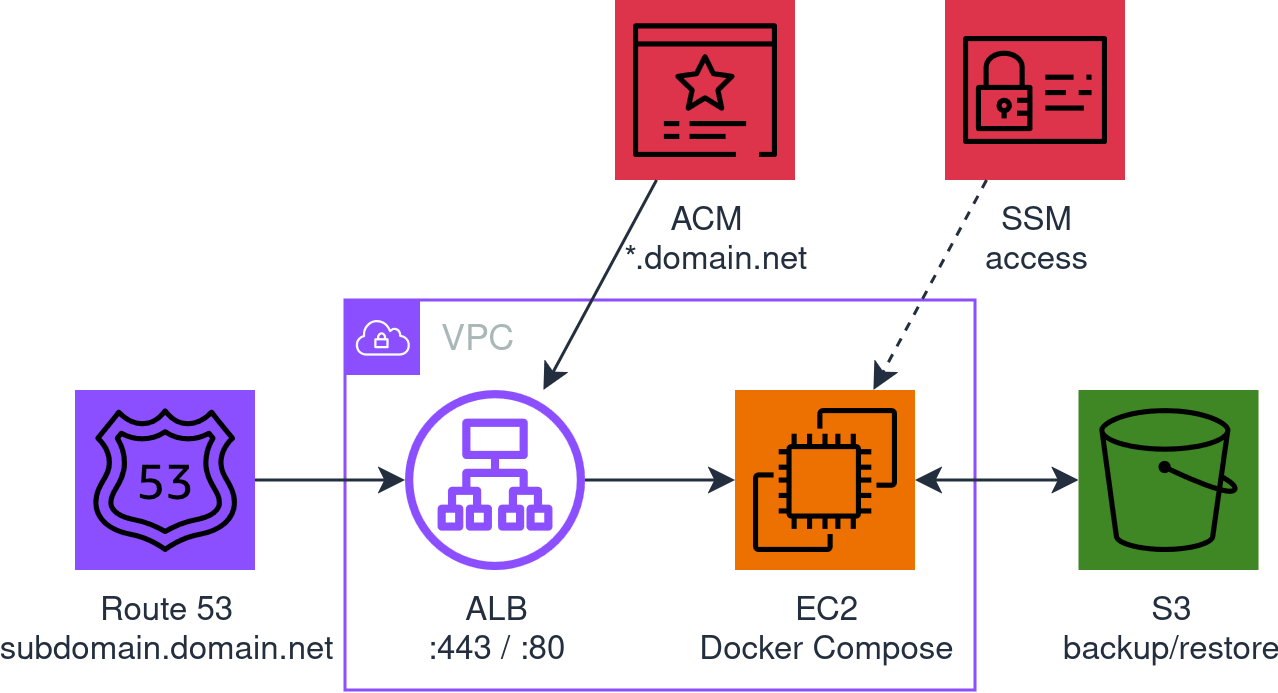
Il punto non è far partire Docker nel cloud, ma è tutto quello che ci sta intorno: HTTPS, dominio custom, accesso alla macchina, backup dei dati, e la possibilità di ricostruire o buttare giù tutto con un comando.
Con IaC puoi gestire agilmente HTTPS, dominio custom, backup, accesso e cleanup: tutto in un posto, tutto versionato, tutto replicabile. Senza IaC, ogni volta riparti da zero.
Le opzioni classiche:
- Setup manuale di una EC2: SSH, installi Docker, configuri nginx, certbot e preghi. Lento, fragile e difficile da riprodurre.
- ECS/Fargate: task definition, service discovery, cluster .. per cosa? Usare Fargate per un singolo container è come usare un TIR per portare la spesa a casa.
- Docker su EC2 con Terraform: un
terraform applyper tirare su, unbash scripts/destroy.shper buttare giù. Backup incluso.
La terza opzione è quella che ho scelto perché ha l’architettura più semplice .. e la parte più complessa dipende dal tuo user data !
L’architettura dell’immagine qui sopra è generata direttamente dal codice Terraform (spoiler), a partire dal codice del repo, dove puoi trovare il README.md e tutti i dettagli per utilizzarlo.
Ma andiamo per ordine. La terza opzione si può implementare in 1024 modi diversi: quale tool IaC ? Come gestisci HTTPS ? Come accedi alla macchina ? Dove salvi i backup ? Come gestisci il DNS ? Che AMI usi ? Dipende. Il punto è farsi le domande giuste.
Da buon developer pigro, ogni scelta ha un unico criterio: meno effort, in termini di tempo, costi, o entrambi. E quando il meno effort non basta a decidere, la via più pulita è un sistema minimal: sai cosa c’è, sai cosa manca, niente sorprese.
Perché Terraform e non CDK
| Terraform | CDK | |
|---|---|---|
| Linguaggio | HCL: dichiarativo, semplice | TypeScript/Python: potente ma verboso per infra semplice |
| Stato | File locale, zero dipendenze | Richiede CloudFormation stack, S3 bucket per asset |
| Bootstrap | terraform init |
cdk bootstrap già crea risorse nell’account AWS |
| Curva di apprendimento | Bassa per infra semplice | Serve conoscere sia CDK che CloudFormation .. e le loro magagne |
| Distruzione | terraform destroy: pulito, prevedibile |
cdk destroy, che a volte lascia risorse orfane |
Per un workshop effimero gestito da una sola persona, Terraform con stato locale è il minimo effort. CDK ha senso quando l’infra cresce, serve logica complessa, o c’è un team coinvolto.
Le scelte e perché
| Scelta | Perché (meno effort) | L’alternativa scartata (più effort) |
|---|---|---|
| ALB + ACM | Certificato HTTPS gratis, rinnovo automatico, niente certbot/nginx | Let’s Encrypt su EC2: porta 80 aperta, cron per il rinnovo, più pezzi mobili |
| SSM invece di SSH | Niente chiavi, niente porta 22, audit trail su CloudTrail | SSH key pair, regole SG, bastion se subnet privata |
| S3 per backup | Costa niente, sopravvive alla EC2, CLI semplice | EBS snapshot: legato al ciclo di vita dell’istanza, più complicato da ripristinare |
| Route 53 hosted zone | Validazione DNS per ACM, alias record per ALB, tutto gestito da Terraform | DNS solo esterno: validazione manuale del certificato o HTTP challenge |
| Amazon Linux 2023 minimal | AMI pulita, ci installi solo quello che serve | AL2023 standard: non ha Docker comunque, ma ha centinaia di pacchetti in più che non servono |
docker compose up --build |
Funziona sia con build che con image |
Logica separata per build vs pull: complessità inutile |
| State locale | Il workshop è effimero, un solo operatore, niente team | Remote state (S3 + DynamoDB): costi e setup per zero benefici |
| VPC condizionale | Tre modalità: usa una VPC esistente, cerca la default, o creane una nuova | VPC sempre nuova: spreco per un workshop che gira nella default VPC |
| S3 bucket condizionale | Se ne passi uno, lo usa. Se no, lo crea con il nome del dominio | Bucket sempre nuovo: spreco per chi fa tanti workshop e ne gestisce solo i backup |
Cosa ho imparato (passando alla pratica)
L’AMI giusta e quanto disco serve
Da buon developer pigro, invece di leggere la documentazione, un comando per vedere cosa c’è:
aws ec2 describe-images \
--filters "Name=name,Values=al2023-ami-*-x86_64" \
--owners amazon \
--query 'reverse(sort_by(Images, &CreationDate))[:10].[Name, BlockDeviceMappings[0].Ebs.VolumeSize]' \
--output table
Tre varianti: la minimal (2 GB), la standard (8 GB), la ECS-optimized (30 GB). La ECS ha Docker di serie ma è pensata per girare in un cluster ECS, non su una EC2 standalone. La standard e la minimal non hanno Docker: va installato in entrambi i casi.
A quel punto, cosa ha in più la standard ? SSM agent e qualche centinaio di pacchetti che non servono. La pagina di confronto pacchetti lo conferma: niente Docker, niente buildx, niente che cambi la situazione.
La minimal è la scelta più pulita: ci installi Docker, SSM agent e buildx nello user data, e sai esattamente cosa c’è sulla macchina. L’unica accortezza: il disco da 2 GB non basta, metti volume_size = 20 e non ci pensi più.
ssm-user non è root
Quando ti colleghi con aws ssm start-session, sei ssm-user. Non hai accesso al socket Docker. Tutto va fatto con sudo. I comandi mandati con aws ssm send-command invece girano come root, quindi il sudo è incorporato.
buildx: se non c’è, niente build
Da Docker Compose v2.17+ il flag --build richiede buildx >= 0.17.0. L’AMI minimal non ce l’ha. Senza buildx, docker compose up --build fallisce anche se nessun servizio usa build: lo installi nello user data e non ci pensi più.
Quella maledetta cache
Dopo un destroy + redeploy, la nuova hosted zone Route 53 ha nameserver diversi. Aggiorni i NS sul provider DNS, tutto sembra a posto. Ma dal browser non funziona niente.
dig @8.8.8.8 ti dice che è tutto ok. Ma il tuo resolver locale no.
Quello che succede: il resolver del tuo ISP ha il vecchio SERVFAIL in cache, e finché non scade, per lui quel dominio non esiste.
La soluzione: cambi temporaneamente il DNS locale a Google (8.8.8.8) e aspetti che la cache del tuo provider scada: dicono 5-10 minuti, ma a volte (molto) di più.
C’è altro da aggiungere ?
Quando non si tratta di un workshop di qualche ora, ma di qualcosa che dura settimane o mesi, vale la pena investire effort in più per far reggere il sistema nel tempo ma ricordandosi che è sempre una soluzione temporanea !
- Più subdomain: più applicazioni sullo stesso ALB, con routing rules, target group separati, e potenzialmente più container sulla stessa EC2 o, se proprio serve, EC2 dedicate per servizio
- Schedulazioni tattiche: start/stop della EC2 per risparmiare fuori orario, backup periodici con EventBridge + SSM, non solo al destroy
- Allarmi CloudWatch: monitoraggio base (CPU, disco, health check) con notifiche SNS
- Auto-recovery: ASG con min=max=1 per sostituire istanze che muoiono (lo user data ripristina tutto da S3)
- Spot instance: per workshop che tollerano interruzioni, costi ridotti del ~70%