Una tela dove testare le potenzialità di un database
In questi giorni ho partecipato ad una competizione, l’hackathon H0, che chiedeva frontend su Vercel e un database AWS. Il database era il punto che mi ha incuriosito: avevo la possibilità di giocare con un database e metterlo sotto stress gratis ? Non potevo farmi scappare questa opportunità !
E se dobbiamo giocare, giochiamo veramente: ho scelto di implementare Territory War perché è una tela di pixel condivisa, stile r/place, dove più squadre dipingono in tempo reale, un pixel per persona alla volta. Il problema vero non è disegnare: è tenere una sola tela coerente quando tanti scrivono sulle stesse celle, magari da regioni diverse, senza che due scritture diano un risultato ambiguo e senza perderne una in silenzio ..
E qui c’è la domanda che mi ha incollato alla competizione: il piazzamento puro è “vince l’ultimo che scrive”, e lo fa bene anche un database a consistenza eventuale, ma quando siamo a livello globale ? La consistenza forte diventa il requisito quando vuoi una sola tela identica per tutti e in ogni regione: una scrittura committata da una parte dev’essere subito vera dall’altra, e due scritture sulla stessa cella non possono lasciare due verità diverse.
Un database per ogni occasione
Quale database dipende da cosa ti serve: ecco i tre ammessi a confronto.
| database | consistenza | multi-region | modello | quando conviene |
|---|---|---|---|---|
| Amazon DynamoDB | eventuale con le global table (forte solo in single-region) | active-active ma eventuale | chiave-valore | scala enorme chiave-valore, quando l’eventuale va bene |
| Amazon Aurora PostgreSQL | forte, ma writer singolo | replica asincrona (Global Database), non active-active | relazionale SQL | carichi relazionali in una regione, letture distribuite |
| Amazon Aurora DSQL | forte | active-active | relazionale SQL, Postgres-compatibile | dati relazionali, globali e coerenti, con più regioni scrivibili |
Amazon DynamoDB, tra regioni, diverge per un istante e risolve i conflitti con “vince l’ultimo che scrive” in silenzio: verità diverse in posti diversi. Amazon Aurora DSQL no, è active-active a consistenza forte: una scrittura committata è subito vera ovunque, e due scritture sulla stessa cella entrano in conflitto invece di sovrascriversi di nascosto. Per questo gioco servono relazionale, globale e coerente insieme: quindi DSQL, ed è il motivo per cui ho puntato sulla track million-scale.
E se il globale non servisse ? Dipende dal modello dei dati. Per un gioco come questo, relazionale e transazionale, meglio Amazon Aurora PostgreSQL; Amazon DynamoDB conviene quando il modello è chiave-valore e la scala conta più della relazione. DSQL ha senso quando servono insieme relazionale, globale e coerenza forte: togline uno dei tre e una delle altre due basta.
Le regole del gioco
L’unica regola “visibile” ai giocatori è il cooldown: un pixel ogni N secondi a testa, il ritmo del gioco di r/place. Il cooldown blocca il doppio clic, ma dietro le quinte, da buon meridionale, come faccio a fermare richieste dello stesso giocatore che arrivano nello stesso istante per due schede aperte con la stessa identità ?
Sotto al cofano il cooldown si appoggia a un timestamp per giocatore, l’istante dell’ultimo piazzamento salvato nel database: a ogni piazzamento, nella stessa transazione, il sistema legge quel timestamp e, se sono passati N secondi, lo aggiorna e scrive il pixel. Tenere controllo e scrittura nella stessa transazione è la regola “nascosta” del gioco: con la REPEATABLE READ ogni transazione vede una foto coerente dei dati e due che toccano la stessa riga vanno in conflitto; quella che fallisce, al retry, trova il cooldown già aggiornato. E lo stesso principio tiene la cella contesa tra giocatori diversi: non può restare con due proprietari, una sola verità. Quindi la correttezza sta nella transazione DSQL: lato browser AWS AppSync Events aggiorna la tela in tempo reale, e un evento perso ritarda al massimo un refresh, non fa perdere un pixel.
L’identità però è solo un id nel browser: chi vuole apre più finestre e gioca come più giocatori perché il limite vale per identità, non per persona, ma per un gioco senza premi va bene. E nel momento in cui si fa sul serio, sarà introdotta l’autenticazione !
Conoscere DSQL prima di costruirci sopra
Isolamento e conflitti
DSQL lavora a un solo livello di isolamento, REPEATABLE READ, e rifiuta SERIALIZABLE. SERIALIZABLE è il livello più stretto: fa come se le transazioni girassero una dietro l’altra, in fila, senza sovrapposizioni; è il più sicuro e il più costoso. REPEATABLE READ è un gradino sotto: ogni transazione vede una foto coerente dei dati presa all’inizio, ma due transazioni che scrivono la stessa riga vanno in conflitto.
E qui DSQL ha il suo tratto: la concorrenza è ottimistica (optimistic concurrency) e senza lucchetti (lock-free). Postgres, sulla seconda scrittura della stessa riga, mette un lucchetto e la fa aspettare; DSQL no, lascia correre, e quando due scritture si pestano il conflitto salta fuori solo al momento di salvare, con l’errore 40001. Non lo sai prima, lo scopri al COMMIT: per questo il piazzamento ritenta, rilegge e riapplica. Conoscere questo prima di costruirci sopra è metà del lavoro.
Da buon informatico pigro e squattrinato, non ho usato DSQL per scrivere la logica: è una risorsa AWS che costa. Postgres locale ha l’isolamento SERIALIZABLE che produce lo stesso 40001 dell’optimistic concurrency, così ho validato offline, gratis, che il timestamp del cooldown fosse controllato nella stessa transazione della scrittura del pixel e che i conflitti fossero gestiti, prima di deployare su AWS.
Lo scoring
Il punteggio ha due modalità. Quella di default è semplice: conta le celle di una squadra più i lati che ha in comune con se stessa, e premia chi sta compatto. Quella interessante è per aree connesse: il punteggio è la somma del quadrato della dimensione di ogni territorio contiguo, così un fronte unito vale molto e spezzare in due un’area grande la penalizza. È lo scoring che dà senso al gioco.
Calcolarlo dentro il database vorrebbe dire una query ricorsiva che, partendo da una cella, raggiunge tutte quelle attaccate della stessa squadra. Sul cluster reale non regge: il risultato intermedio cresce con il quadrato delle celle e supera il limite dei 300 secondi per transazione già intorno alle 1300 celle contigue. Lo stesso conto fatto fuori dal database, in Node, con un algoritmo che unisce le celle vicine in gruppi (union-find), è lineare: l’intera tela in pochi millisecondi, un milione di celle in un quarto di secondo.
Lo scoring per aree lo calcolo lato app: la versione ricorsiva resta solo come prova che su DSQL gira ma non scala. I numeri sono nel report scoring.
I vincoli, sulla mia pelle
La maggior parte di questi paletti non li ho letti nella documentazione, li ho incontrati uno ad uno usando DSQL.
Per svuotare le tabelle, in locale usavo TRUNCATE; su DSQL non esiste: sono passata a DELETE.
Poi, provando lo script che dipinge la tela con quattro squadre, ho fatto un reset e il DELETE è esploso: una transazione modifica al massimo 3000 righe, e una tela piena ne tocca molte di più. Soluzione: il reset cancella a blocchi sotto le 3000.
Applicando lo schema, la seconda CREATE TABLE nella stessa transazione è stata rifiutata: una sola istruzione DDL per transazione, così lo schema va applicato un comando alla volta.
E niente foreign key perché su DSQL non ci sono: l’integrità tra tabelle (un giocatore deve appartenere a una squadra che esiste) è da garantire con l’app.
Il limite dei 300 secondi per transazione è saltato fuori misurando quanto reggeva la query ricorsiva dello scoring (paragrafo precedente).
E per connettersi non c’è una password: DSQL vuole un token IAM a breve scadenza, firmato per la regione del cluster. In multi-region è un dettaglio interessante: il token di una regione non vale per l’altra, ognuna ha il suo host e la sua firma.
Conflitti veri vs sovrascritture
Volevo comprendere se si potevano far vedere i conflitti in un video. Per provocarli ho lanciato due script che dipingono le stesse celle nello stesso momento.
A occhio sembrava funzionare: alcuni pixel cambiavano colore, altri restavano, e pareva di vedere i conflitti dal vivo. Come prova del nove, ho contato i retry da 40001, ed è emersa la verità: quasi tutti erano sovrascritture semplici, una dopo l’altra, dove vince l’ultimo che scrive, senza conflitto. Solo una parte delle sovrascritture erano davvero collisioni simultanee.
Active-active, provato con un test
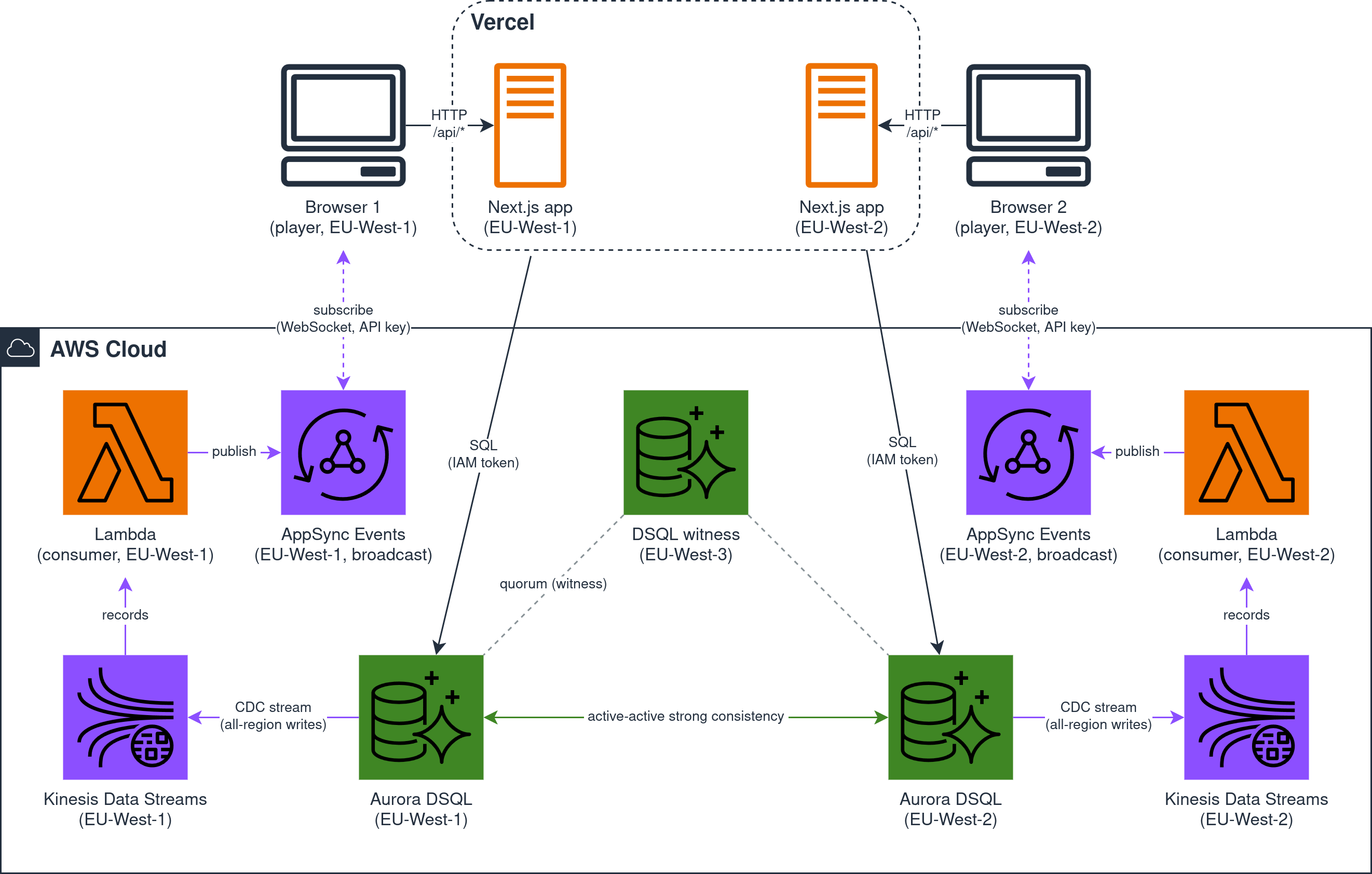
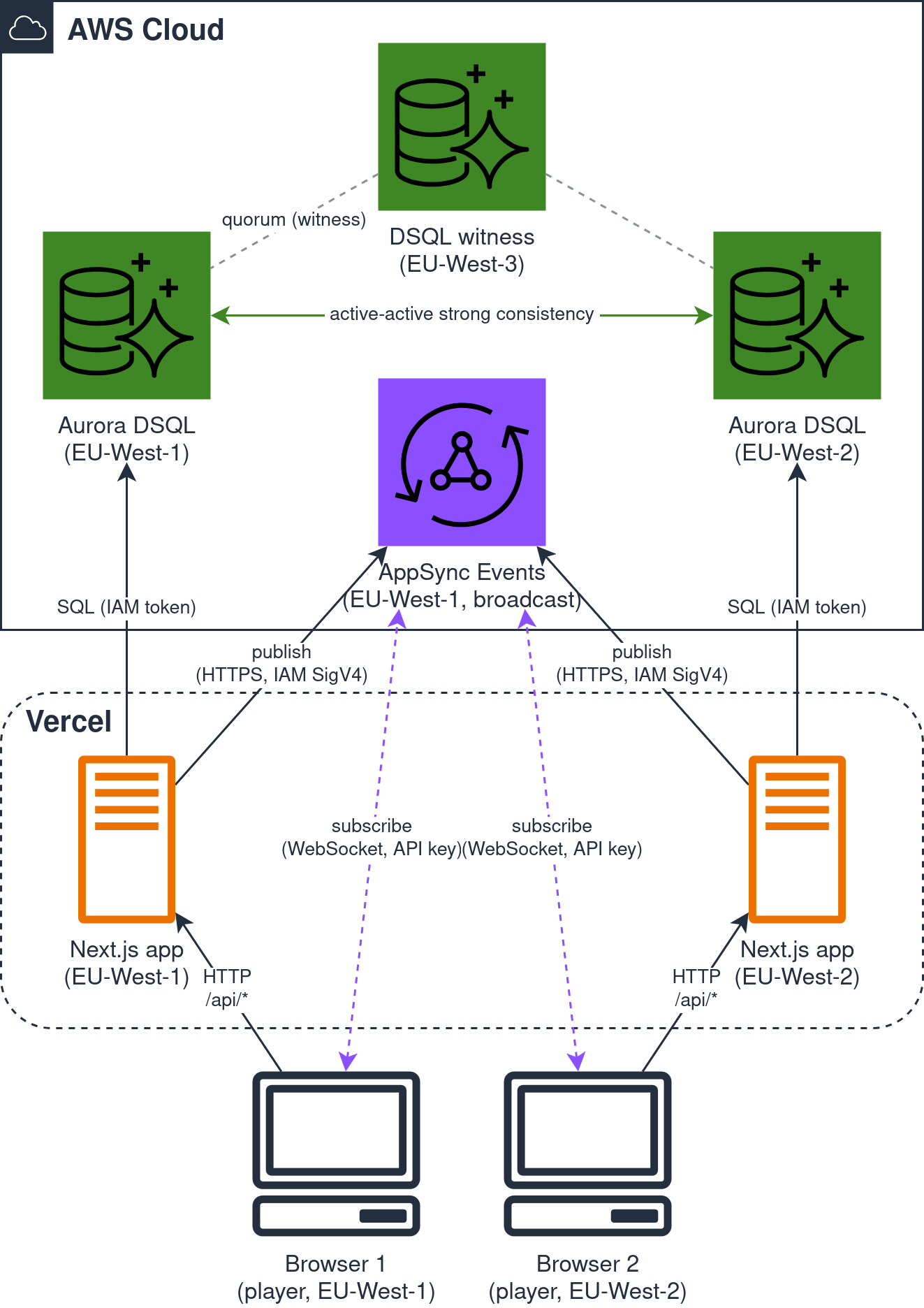
DSQL multi-region è active-active: due regioni, entrambe scrivibili, sullo stesso database logico (più una terza regione “witness” che fa solo da arbitro per il quorum, senza un endpoint da interrogare; le due attive devono stare sullo stesso continente, niente cross-continente).
Che sia davvero coerente non si vede a occhio, ma lo dimostra un test: scrivere su una regione e rileggere dall’altra, nei due versi, e il dato c’è subito; e due scritture sulla stessa cella da regioni diverse danno lo stesso conflitto 40001 di prima. È la prova della consistenza forte cross-region, quella che le global table a consistenza eventuale non danno. Ed è la feature che, da ex DBA, avrei voluto avere ..
I dettagli del test, coi comandi per riprodurlo, sono nel report DSQL.
Cosa manca per essere davvero million-scale ?
Quello che ho costruito dimostra che si può avere un sistema scalabile a milioni di giocatori su una tela gestita a livello globale. Ma per averlo davvero, cosa manca ?
Per la competizione c’è un deploy Vercel per regione, ma sono due URL distinte. Vercel non instrada da solo l’utente verso l’app più vicina, perché sono due progetti separati: instrada dentro un progetto, non fra progetti diversi. Oggi l’URL lo sceglie l’utente, e l’instradamento automatico verso la regione più vicina manca. Con AWS lo darebbe Amazon Route 53 con routing a latenza, che manda ogni utente verso l’endpoint regionale più vicino.
In questo momento ogni app parla con l’endpoint del cluster della propria regione, e dentro la regione DSQL gestisce da solo la failure di una availability zone, in modo trasparente. E se l’endpoint DSQL di una regione diventa irraggiungibile ? Il dato non si perde, è già vivo nell’altra perché è active-active; a mancare è il punto di connessione: l’endpoint è regionale, perciò l’app puntata su quella regione resta senza interlocutore. Servirebbe un failover automatico verso l’endpoint dell’altra regione, che DSQL non offre nativo: lo deve gestire il client, scegliendo l’endpoint sano e rifirmando il token per la sua regione.
E il punto più interessante: il realtime per regione. Oggi AppSync è una sola API in una regione, richiamata anche da app di altre regioni, ed è il collo di bottiglia perché il database è già distribuito. La strada pulita non è un secondo sistema di eventi da tenere allineato al database a mano, ma un realtime che nasce dal dato già committato. Un AppSync per regione, da solo, non basta: se ognuno trasmettesse solo le scritture della propria regione, le tele vedrebbero una parte degli eventi, non la stessa partita. Qui arriva in aiuto il change data capture (CDC) di DSQL: legge le scritture committate e le consegna ad Amazon Kinesis Data Streams, uno stream per regione che riceve tutte le scritture del cluster, non solo quelle di quella regione; da quel flusso si alimenta l’AppSync di ogni regione, così ogni tela riceve l’intero gioco. Il realtime diventa una conseguenza del dato, non un sistema parallelo da tenere coerente. È una feature in preview, ma è esattamente la direzione giusta. E che lo stream possa consegnare lo stesso evento più di una volta, e non in ordine, non è un problema qui: sulla tela vince comunque l’ultimo che scrive per cella.