Perché questo progetto
Ho pensato di implementare questo repo perché non ne avevo ancora uno di questo tipo e, lavorando sull’ingestion dei dati con Glue da tempo, volevo raccogliere in un posto solo tre punti: come strutturare il codice perché resti testabile, quali feature di Firehose o Glue usare e con quale criterio, e qualche chicca di Docker e Terraform che mi ero sempre ripromessa di aggiungere da qualche parte.
In più, non avevo mai messo in piedi Glue streaming da zero, e per un progetto personale mi serviva un banco di prova per confrontare Iceberg e Parquet + partition projection sullo stesso flusso di dati e sotto le stesse query Athena, in modo da capire quando una soluzione conviene rispetto all’altra e per quali motivi.
In questo progetto c’è molta della mia esperienza accumulata negli ultimi anni, mescolata a un paio di curiosità che non avevo ancora avuto modo di testare. Quindi non ci sono vere e proprie sfide, perché per quelle c’ho già sbattuto la testa tanto tempo fa. Quello che racconto qui sono scelte mirate, dettate dal conoscere questi servizi a menadito.
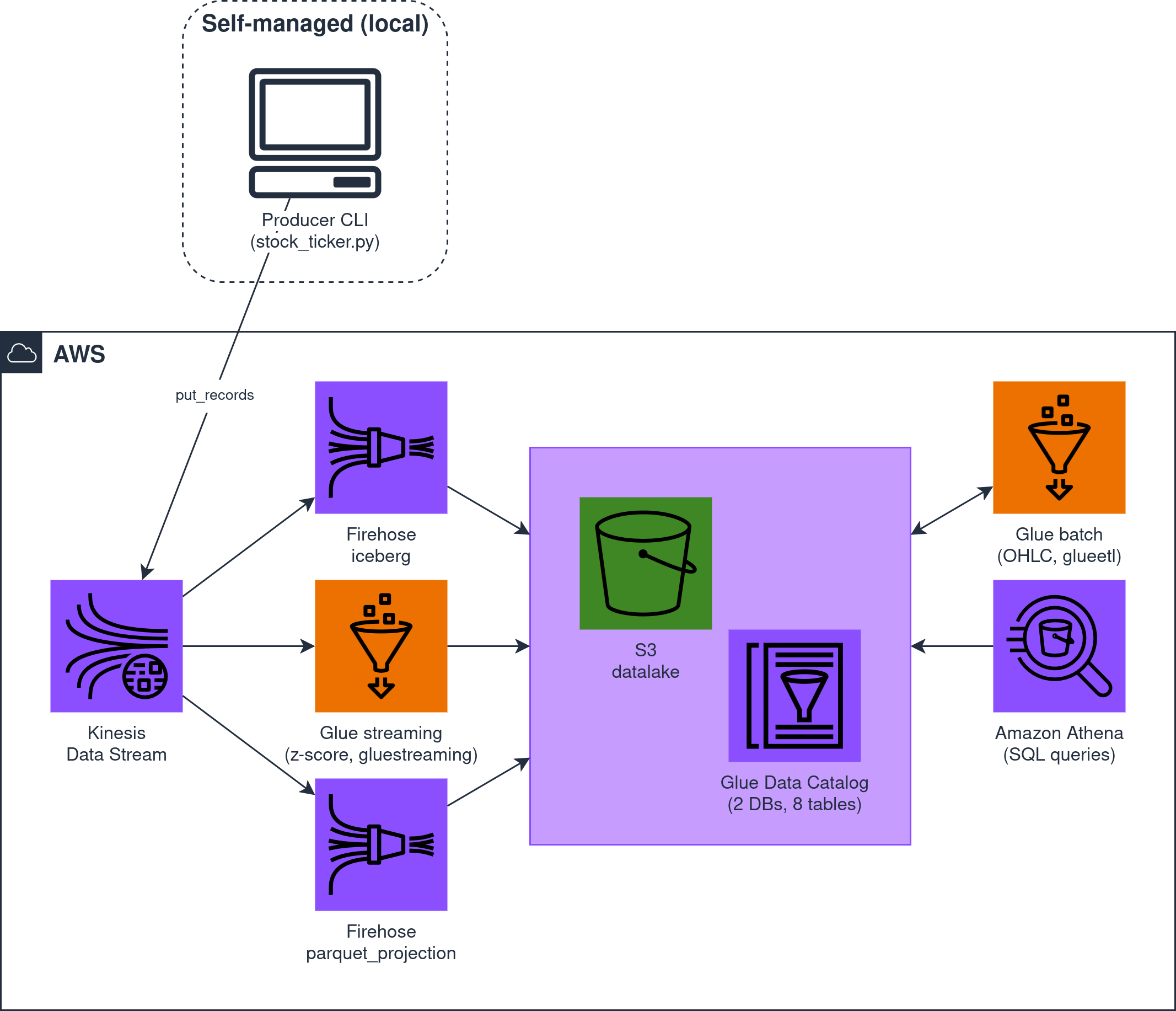
L’architettura nell’immagine descrive proprio questo progetto: un producer Python che simula stock ticker, un Kinesis Data Stream come unico punto di ingresso, due Firehose che persistono lo stesso flusso in due formati diversi (Iceberg e Parquet), due Glue job che scrivono in tutti e due i formati (uno in batch per il calcolo OHLC su 1m e 5m, uno in streaming per il rilevamento di anomalie via z-score su sliding window), e Athena che interroga entrambi i database.
Le scelte e perché
L’obiettivo era quindi mettere a confronto l’uso di Glue in batch e Athena a partire da un database basato su Iceberg e uno basato su Parquet + partition projection.
| Scelta | Perché (meno effort) | L’alternativa scartata (più effort) |
|---|---|---|
Producer Python con boto3.put_records |
Codice originale, scenari controllabili (stable, trend, spike, mixed), test pytest |
Kinesis Data Generator: webapp con Cognito, poco mantenuta |
| Parquet | Partizionato con la projection pronto all’uso | L’alternativa obbliga a far passare un Crawler o schedulare MSCK REPAIR TABLE |
--LOAD_DATA_MODE (parquet, spark, iceberg) |
Un parametro espone tre strategie di lettura confrontabili nello stesso deploy | Tre Glue job separati |
Wheel + --additional-python-modules |
pip install esplicito al boot del worker, pip install -e . in locale: stessa semantica di import |
--extra-py-files con zip o wheel: comportamento meno deterministico tra versioni Glue |
Wrapper di 3 righe in src/glue_jobs/ |
3 righe che chiamano run() dal wheel: tutta la logica testabile in pytest |
Tutto il codice nel script_location: niente pytest sui main |
Lo schema dei record che il producer scrive (ticker_symbol, sector, price, change, event_timestamp) non l’ho inventato: è quello della demo Firehose ufficiale di AWS. Quella demo configura una sola Firehose; il PoC ne configura due in parallelo, una per Iceberg e una per Parquet+projection, per confrontare i due storage sopra la stessa sorgente. Il Kinesis Data Generator è il tool che la demo usa per generare il dataset, ma riscriverlo come producer Python con boto3 mi ha dato il controllo sugli scenari (stable, trend, spike, mixed) e li ha resi testabili in pytest. Gli scenari servono al Glue streaming, che si occupa di anomaly detection: spike inietta picchi di prezzo controllati per validare il rilevamento z-score sulle anomalie, stable e trend fanno da baseline per evitare falsi positivi.
Da buon developer pigro, il criterio è sempre lo stesso: meno effort, in termini di tempo, codice o costo. Su due voci della tabella vale la pena scendere nel dettaglio: il --LOAD_DATA_MODE solleva la questione delle modalità di lettura, il wrapper di 3 righe porta dietro l’organizzazione del codice che rende possibile il TDD. Le racconto una alla volta, partendo dalla lettura.
Performance e modalità di lettura
Per capire perché esistono i tre LOAD_DATA_MODE, bisogna partire dalla scelta della partition projection come strategia di partizionamento. L’alternativa sarebbe stata registrare le partizioni in Glue Catalog tramite Crawler o MSCK REPAIR TABLE, permettendo di leggerle lato Glue con from_catalog e di sfruttare il push-down predicate che è fino a 5x più rapido del filtro post-read. GetPartitions può incontrare limiti di API rate, LIST S3 invece scala perché è paginato. La projection evita la registrazione (la tabella sopra ricorda perché meno effort), ma porta dietro un vincolo:
Partition projection is usable only when the table is queried through Athena. If the same table is read through another service such as Amazon Redshift Spectrum, Athena for Spark, or Amazon EMR, the standard partition metadata is used.
Quindi un Glue job che leggesse il database Parquet+projection via from_catalog ricadrebbe sui partition metadata standard, che per una tabella projection non sono registrati nel Catalog: niente partition info disponibile lato Glue, full scan su niente, strada inutilizzabile. Tocca andare diretti su S3 con spark.read.parquet, lasciando a Spark la partition discovery via LIST dei prefissi. La projection vale solo quando la stessa tabella la interroghi da Athena, dove fa il suo lavoro: niente chiamate GetPartitions al Catalog, partizioni calcolate in memoria a partire dal template.
Da qui le tre modalità del parametro LOAD_DATA_MODE esposte dal Glue batch:
| Mode | Cosa ritorna | Costo extra rispetto a spark |
Quando ha senso |
|---|---|---|---|
parquet |
DynamicFrame Glue (from_options(connection_type="s3", format="parquet")) |
Schema discovery on-the-fly + ResolveChoice (encoding esplicito di colonne con tipi inconsistenti come “choice”); overhead di memoria del wrapper | Dati raw “sporchi” o con schema instabile, dove serve la flessibilità del DynamicFrame |
spark |
DataFrame puro (spark.read.parquet(path)) |
Nessun overhead aggiuntivo: lo schema è quello che è | Dati Parquet con schema stabile, come quelli generati da Firehose. È il path più diretto |
iceberg |
DynamicFrame da from_catalog, ma il read passa per i metadata Iceberg (manifest list, column statistics) |
Lettura del manifest list (costo fisso piccolo); in cambio file skipping su filtri non-partition | Dati gestiti come tabella Iceberg con MERGE/UPSERT, e quando i filtri tipici sono su colonne con statistics utili (timestamp, ticker, ecc.) |
Le caratteristiche del DynamicFrame sono descritte nella documentazione Glue:
A
DynamicFrameis similar to aDataFrame, except that each record is self-describing, so no schema is required initially. Instead, AWS Glue computes a schema on-the-fly when required, and explicitly encodes schema inconsistencies using a choice (or union) type.
Il pattern di accesso fa la differenza tra spark/parquet e iceberg all’aumentare del volume:
| Pattern di accesso | Volumi piccoli (~1 GB) | Volumi grandi (50-100 GB, molti file) |
|---|---|---|
| Read completa, no filter | iceberg leggermente penalizzato dal costo fisso del manifest read |
iceberg comparable: il costo del manifest si diluisce sull’I/O totale |
| Filter su partition column | comparable: entrambi fanno pruning di base | iceberg vince: il manifest list è O(1) sul numero di partizioni, il list S3 cresce con O(n) |
| Filter su non-partition column | iceberg vince via column statistics nei manifest: salta interi file senza leggerli |
iceberg vince in modo netto: parquet/spark devono leggere e filtrare a runtime |
In pratica, per grandi volumi, vince Iceberg perché si tiene da parte, per ogni file Parquet, il valore minimo e massimo di ogni colonna. Quando una query filtra (ad esempio ticker_symbol = 'AMZN'), la query engine guarda quei min/max e capisce subito quali file possono contenere il dato e quali no; i file scartati non vengono nemmeno aperti.
Da buon developer pigro ho preferito leggere la documentazione ed evitare di fare un benchmark generico perché il pattern di accesso è già chiaro. Poi, caso per caso, sarà da scegliere in base al tipo di accesso ai dati necessario.
TDD a tre strati sui Glue job
I Glue job sono noti per essere difficili da testare: ti serve GlueContext, ti serve un Iceberg MERGE INTO vero, ti serve Spark configurato come gira sul worker. Non rinuncio al TDD nemmeno qui: separo il codice in tre strati con confini netti.
- Logica pura Python (parsing argomenti, naming derivation, scenari del producer): pytest diretto, zero dipendenze AWS o Spark
- Trasformazioni Spark core (classi
OhlcAggregator,ZScoreDetector):SparkSession.builder.master("local[1]")come fixture, DataFrame costruiti da literal. Le classi sono DataFrame-in / DataFrame-out, totalmente isolate - Orchestrator
run(): prendeargs,spark,glue_context,read_*_fn,write_fncome parametri. I test passano unGlueContextmockato e funzioni source/sink di test. Il principio è “il job costruisce, le classi consumano”: tutta la conoscenza di Glue vive nel_cli_entrypointche istanzia source e sink prima di chiamarerun()
Quello che resta fuori dal pytest è solo l’integrazione vera (Glue Data Catalog, Iceberg MERGE INTO, Kinesis Stream): coperta dai JSON in tests/integration/ che girano sia in locale via docker compose, sia su AWS via aws glue start-job-run. Lo stesso file pilota entrambi: niente duplicazione tra config AWS e script di test locale.
A corredo, docker-compose.yaml espone due profili che puntano alle immagini ufficiali AWS, glue4 (Spark 3.3, Python 3.10) e glue5 (Spark 3.5, Python 3.11, Iceberg built-in): make test-integration-local PROFILE=glue5 (default) o PROFILE=glue4. Le mount path differiscono fra le due immagini (/home/glue_user/ vs /home/hadoop/), ma local_test.sh lavora con path relativi e lo stesso JSON gira su entrambe. È la scorciatoia per validare lo stesso script su due versioni di Glue prima di un upgrade della glue_version.
Il Python developer che è in me ora ha una grande soddisfazione.
Cosa ho imparato (passando alla pratica)
Firehose con format conversion: 64 MB minimi e schema cached
Firehose accumula i record in un buffer prima di scriverli su S3, e fa il flush in due casi: quando il buffer raggiunge una certa dimensione (buffering_size, in MB) o quando passa un certo tempo (buffering_interval, in secondi).
Da qualche tempo ormai, i valori minimi di questi buffer sono stati ridotti: buffering_size parte da 1 MB e buffering_interval da 0 secondi.
Per un PoC con volumi piccoli, mi interessava un flush rapido: ho impostato buffering_size = 1 MB e buffering_interval = 60s, contando sul fatto che il flush sarebbe scattato sul tempo prima che sulla dimensione.
Sul Firehose Iceberg è andata liscia. Sul Firehose Parquet+projection, no:
Error: InvalidArgumentException: BufferingHints.SizeInMBs must be at least 64
Quando un Firehose ha attiva la conversione di formato (data_format_conversion_configuration, che converte il JSON in arrivo in Parquet prima di scriverlo su S3), AWS impone buffering_size >= 64 MB. Sul Firehose Iceberg la conversione non c’è (Iceberg si appoggia al suo formato nativo), quindi 1 MB è accettato. Sul Parquet+projection ho alzato il valore a 64 MB e morta lì: il flush continua a essere governato da buffering_interval = 60s, e, per i volumi del PoC, i 64 MB non si saturano mai. La latenza percepita è invariata.
Stesso Firehose Parquet+projection, secondo round: dopo l’apply, i record finivano in s3://bucket/parquet_projection/_firehose_errors/format-conversion-failed/ invece che in raw/. Causa: il producer scrive event_timestamp come ISO 8601 con T e timezone ("2026-04-23T20:48:32+00:00"), ma l’OpenXJsonSerDe usato da Firehose accetta come Hive timestamp solo yyyy-MM-dd HH:mm:ss[.fff]. Il Firehose Iceberg accetta ISO 8601 nativamente, il Parquet+projection no. Tre opzioni:
- cambiare il producer per scrivere epoch millis: era la più pulita, ma ammettendo che non si potesse intervenire sul producer, dove avrebbe avuto senso gestire la conversione a valle ?
- mettere un Lambda processor in Firehose per riformattare il timestamp: un’azione così semplice, ripetuta su ogni record, valeva la pena scomodare una Lambda ?
- tipare
event_timestampcomestringnelle Glue raw tables, e fare il cast in Spark conF.to_timestamp("event_timestamp")quando serve: quando Spark ha tutti i dati in pancia, può gestire la tipazione con una complessità O(n) ma parallelizzata
Scelto il terzo. Il tipo “naturale” vive nel layer dove i dati nascono (raw popolato da Firehose, string per portabilità), il tipo timestamp compare in aggregated_* e anomalies dove i DataFrame sono già in mano a Spark.
Applicato il fix, ho aggiornato lo schema della Glue raw table cambiando il tipo di event_timestamp da timestamp a string. terraform apply è andato a buon fine, ma per i ~5 minuti successivi i record continuavano a finire negli _firehose_errors/. Causa: Firehose tiene in cache lo schema_configuration della Glue table per evitare di interrogare il Catalog ad ogni record. AWS documenta “up to 15 minutes” di cache; nei test ne sono bastati 5 prima di vedere i record arrivare puliti su raw/. Per saltare l’attesa, terraform apply -replace="aws_kinesis_firehose_delivery_stream.parquet_projection[0]" ricrea il delivery stream e azzera la cache. Per un PoC l’attesa è accettabile; in un caso reale il replace (o aws firehose update-destination direttamente) è la via più veloce.
Il nome del wheel è tutto un programma
In un lontano passato, quando ancora non avevo la gestione dei test locali, avevo avuto la brutta idea di fornire al Glue job il wheel rinominato a dist/glue_common.whl, così da non dover toccare la configurazione ad ogni nuovo upload su S3.
Ma Glue si arrabbia:
LAUNCH ERROR | Installation of Additional Python Modules failed:
ERROR: glue_common.whl is not a valid wheel filename
pip install richiede la forma PEP 427: {name}-{version}-{python}-{abi}-{platform}.whl. L’alias senza versione non passa la validazione fuori dal contesto PyPI.
Quindi da buon developer pigro, qual è la soluzione migliore per fare tutto automaticamente senza dimenticarsi di caricare il nuovo wheel ?
- Terraform legge la versione dinamicamente da
src/glue_common/__init__.pyviaregex(), compone il nome PEP 427 e lo usa come S3 key e source path - al
make patchil filename cambia, Terraform rileva il nuovo file e lo ricarica su S3 da solo
Altra grande soddisfazione.
Iceberg in Glue 5.0: due strade per registrare il catalog
Dopo il fix del wheel, il batch job si è fermato su:
AnalysisException: [TABLE_OR_VIEW_NOT_FOUND]
The table or view 'etl_prototype_demo_iceberg.aggregated_1m' cannot be found
Le tabelle nel Glue Data Catalog c’erano (Terraform le aveva create, le vedevo via aws glue get-tables). Mancava il ponte fra Spark e il Catalog: le chiavi spark.sql.extensions, spark.sql.catalog.glue_catalog.* e spark.sql.defaultCatalog che dicono a Spark “per il catalog glue_catalog, usa l’implementazione Iceberg che si appoggia al Glue Data Catalog”.
È un vincolo tecnico: queste chiavi devono essere applicate prima che la SparkSession sia inizializzata. Una volta che GlueContext(sc) ha creato la SparkSession, una spark.conf.set("spark.sql.catalog.glue_catalog", "...") runtime viene accettata sintatticamente, ma non ha effetto: il catalog non viene registrato e il job risponde “Catalog ‘glue_catalog’ plugin class not found”. Era esattamente il primo tentativo che avevo provato tanto tempo fa prima di leggere diligentemente la documentazione ..
La documentazione Glue per Iceberg elenca due modi equivalenti per applicare le conf nel posto giusto:
Create a key named
--conffor your AWS Glue job, and set it to the following value. Alternatively, you can set the following configuration usingSparkConfin your script.
Le due configurazioni, sotto il cofano, ottengono lo stesso risultato:
-
SparkConf nel codice Python:
sc = SparkContext() conf = sc.getConf() conf.set("spark.sql.extensions", "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions") conf.set("spark.sql.catalog.glue_catalog", "org.apache.iceberg.spark.SparkCatalog") # ... altre conf ... sc.stop() sc = SparkContext.getOrCreate(conf=conf) glueContext = GlueContext(sc) # qui nasce la SparkSession con la conf giustaLa configurazione vive nel codice. L’
sc.stop()+ ricreazione delSparkContextè il momento in cui la configurazione viene “iniettata” prima dell’init della SparkSession. -
--confneidefault_argumentsdi Terraform:locals { iceberg_spark_conf = join(" --conf ", [ "spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions", "spark.sql.catalog.glue_catalog=org.apache.iceberg.spark.SparkCatalog", "spark.sql.catalog.glue_catalog.catalog-impl=org.apache.iceberg.aws.glue.GlueCatalog", "spark.sql.catalog.glue_catalog.io-impl=org.apache.iceberg.aws.s3.S3FileIO", "spark.sql.catalog.glue_catalog.warehouse=s3://${data.aws_s3_bucket.main.id}/iceberg/", "spark.sql.defaultCatalog=glue_catalog", ]) }Glue parsa la stringa concatenata, applica le configurazioni al boot della SparkSession e poi passa il controllo allo script Python.
Ho scelto di configurare il PoC tramite Terraform, perché ? Tre motivi:
- una sola fonte di verità: il
localiceberg_spark_confè definito una sola volta in Terraform e riusato sia dal Glue batch sia dallo streaming via--conf = local.iceberg_spark_confnei rispettividefault_arguments. Nessuna duplicazione job per job, e se domani aggiungo un terzo Glue job riuso lo stessolocalcon una riga - separazione configurazione e codice: il setup del catalog vive in Terraform accanto al
--datalake-formats=iceberg; il Python dei job non sa che esiste un catalog Iceberg, importaglue_common, ricevesparkeglue_contextcome parametri e gira - cambio della config a costo basso: un warehouse, una catalog implementation o un IO diversi si toccano solo in Terraform, senza ricompilare e ricaricare il wheel
La configurazione nel codice invece resta più comoda quando la configurazione del catalog dipende da argomenti che il job riceve a runtime (per esempio un warehouse derivato dal nome del bucket di input passato come --ARG): in quel caso la conf si compone naturalmente nel codice, perché lì hai già gli argomenti risolti. In questo PoC il warehouse è fisso per ambiente, quindi la configurazione in Terraform vince su semplicità.
C’è altro da aggiungere ?
Quando il PoC è stato approvato, si comincia a fare sul serio: c’è da integrare ciò che è stato simulato e da valutare altri servizi e approcci
- API reali: sostituire lo scenario simulato con una vera ingestion. Cambia la natura del producer, non l’architettura
- Apache Flink come alternativa a Glue streaming: ha senso quando servono garanzie più strette sul numero di volte che un evento viene processato (Flink supporta nativamente exactly-once, cioè ogni evento elaborato esattamente una volta; Glue streaming è at-least-once e i duplicati vanno gestiti applicativamente), oppure quando la latenza richiesta è sotto il secondo (Glue streaming, lavorando in micro-batch, è tipicamente nell’ordine dei 5-10 secondi; Flink scende a centinaia di millisecondi)
- Multi-environment deploy: in un PoC, l’ambiente unico basta. In produzione serve separare per testare evolutive senza toccare il dato vivo. Quindi, servono Workspace Terraform o moduli cross-env, con tutte le implicazioni di gestione degli account
- CI/CD: in un PoC il
make teste ilterraform applymanuali bastano. Lavorando in team o su pipeline mission-critical serve automazione (lint, test, build wheel, terraform plan automatici per ogni PR) per intercettare regressioni prima del merge - Cross-account Data Catalog sharing: Lake Formation + RAM + KMS +
assume_role. Quando il datalake aggrega flussi di filiali, dipartimenti, partner, lo schema centralizzato cambia tutto - Data Management: l’evoluzione dello sharing del Data Catalog centralizzato è DataZone, o SageMaker Unified Studio, con la gestione della lineage, dei permessi e di tutta la documentazione per ciascun asset
- Time frame aggiuntivi nel batch come roll-up dai 5m (1h, 1d), non dal raw: ogni livello calcola sopra l’output del precedente, quindi su meno dati. È un approccio classico (cascade ETL) e funziona quando l’aggregato di livello superiore si può ricalcolare dal livello inferiore (l’high di un’ora è il max degli high dei 5 minuti). Non funziona se il calcolo richiede tornare ai valori originali, come mediane o distinct count esatti