Perché tanto interesse per il realtime transcription
Tutto è nato dalla collaborazione con PyCon IT. Alla PyCon IT 2025 hanno messo in piedi una trascrizione live con Whisper locale su Graphics Processing Unit (GPU), basato sul repo realtime-transcription-fastrtc. Con i video di YouTube usati come test, tutto a posto. Con l’audio vero di una sala di conferenza, Whisper ha iniziato ad allucinare: un modello generativo, se gli dai un segnale che non riconosce, non lascia bianco, scrive qualcosa comunque.
Per la PyCon IT 2026 serviva una strada diversa, su un perno non negoziabile: niente allucinazioni. Se il modello non sente, ok, salta una parola. Se sente male, ok, trascrive male. Ma non deve scrivere frasi che non ho pronunciato.
Sistemare direttamente le allucinazioni di Whisper (Voice Activity Detection, tuning dei parametri di decoding, filtri sui logprob, fine-tuning, ..) sarebbe stato un fronte a sé: non avevo il tempo, con tutto il resto da costruire. Whisper più grande non l’ho testato. Altri servizi Speech To Text (STT) generativi a pagamento nemmeno: restano nella stessa categoria di un modello che produce testo token dopo token, quindi il rischio strutturale di invenzione rimane. Per uscire dalla categoria serviva un servizio gestito basato su decoding acustico. E siccome è la PyCon, prendiamoci pure il bonus di disaccoppiare i pezzi e di scriverlo in modo testabile.
Un modello che sbaglia ma non inventa
Partiamo dal motore. Poi da cosa ci sta attorno.
STT: chi sbaglia, chi inventa
Non ho fatto benchmark empirici sui tre. La scelta si è giocata su due assi: struttura del modello (generativo o no) e delivery (self-hosted o managed). Le proprietà in tabella vengono da documentazione di prodotto e dall’osservazione diretta di Whisper alla PyCon IT 2025, non da A/B test.
| Criterio | Whisper locale | Amazon Transcribe Streaming | STT generativo a pagamento |
|---|---|---|---|
| Architettura | generativa (autoregressiva) | non generativa (decoding acustico) | generativa |
| Allucinazioni strutturalmente possibili | sì | no | sì |
| Delivery | self-hosted | managed | managed |
| Setup | GPU + modello | credenziali AWS | credenziali |
| Dipendenza rete | no | sì | sì |
| Costo | hardware on-site | $0.024/min | variabile |
| Latenza dichiarata | 1-15s fine segmento | ~300ms partial | dipende |
Il criterio più importante è l’architettura. Un modello non generativo non può, per costruzione, aggiungere parole che non ha sentito: alla peggio omette o sbaglia. Un modello generativo sì. Gli altri criteri (rete, costo, latenza) sono trade-off secondari, tutti accettabili per un contesto di conferenza: internet c’è, un talk da 30 minuti costa ~$0.72, i partial results arrivano in ~300ms.
Scelta: Amazon Transcribe Streaming. Non perché sia “il migliore” in assoluto, ma perché sta nella categoria che esclude alla radice il problema per cui siamo qui. Il repo video-to-text l’avevo scritto apposta per testare Transcribe come alternativa a Whisper.
Repo nuovo o fork del vecchio ?
L’altra grande scelta: fork di realtime-transcription-fastrtc (quello già usato alla PyCon IT 2025) o repo nuovo che prende solo i pezzi buoni dai due predecessori (realtime-transcription-fastrtc e video-to-text) ?
| Criterio | Fork | Repo nuovo |
|---|---|---|
| Effort iniziale | basso | medio |
| Dipendenze fragili ereditate | FastRTC v0.0.26 | nessuna |
| Architettura | monolitica da smontare | disegnata per il caso d’uso |
| Testabilità | eredita il perimetro esistente | ogni componente in isolamento |
Scelta: repo nuovo. Da buon developer pigro uno sarebbe tentato di forkare, ma quando una dipendenza è fragile (FastRTC v0.0.26 non è uno standard stabile), un fork potrebbe costare più di un rewrite mirato.
Da realtime-transcription-fastrtc tengo il layout screen (sfondo nero, testo grande) e la logica di auto-scroll del frontend. Dal video-to-text prendo il modulo transcribe_service.py e il pattern asincrono con asyncio.Queue + asyncio.gather(). Il resto si butta.
Architettura: monolitica o disaccoppiata ?
Da buon developer pigro, non voglio rifare tutto passando dal Proof of Concept (PoC) al Minimum Viable Product (MVP). I due predecessori hanno già pezzi che girano (il layout screen di realtime-transcription-fastrtc, il transcribe_service di video-to-text), ma sono pezzi di repo diversi, pensati per scopi diversi. Per riciclarli serve che i moduli abbiano confini chiari.
Un’architettura disaccoppiata qui vuol dire avere tre componenti come tre processi separati che si parlano via rete:
- il client audio, che cattura l’audio dal device di sistema e lo invia al server
- il server, che riceve audio, gestisce lo stream verso Amazon Transcribe e pubblica il testo
- il client display, che riceve il testo dal server e lo mostra sul monitor dedicato
L’architettura alternativa è un unico processo (un unico programma in esecuzione) che cattura, trascrive, mostra.
| Criterio | Monolitica | Disaccoppiata |
|---|---|---|
| Deploy | un solo binario | tre componenti |
| Distribuzione su più computer | no | sì (nativa) |
| Testabilità | dipendenze interne | ogni componente in isolamento |
| Overhead di comunicazione | niente | chiamate di rete |
Scelta: disaccoppiata. Funziona sia in sviluppo con tutto su un computer (localhost), sia in conferenza con tre computer separati: client audio in regia vicino al mixer, server su un computer qualsiasi connesso in rete, e client display sul computer che pilota il monitor. La monolitica invece chiude tutto su un solo computer, e il codice accoppia i componenti: test e sostituzione richiedono più lavoro. Con più sale il conto peggiora: servirebbe una copia intera del sistema per sala (audio, server, display per ciascuna), mentre la disaccoppiata condivide un solo server tra tutte le sale, e ogni sala aggiunge solo un client audio e display sullo stesso computer, o, per evitare di tirare un cavo volante, un secondo client display vicino al monitor.
Audio client: browser o standalone ?
L’audio da trascrivere ha sorgenti diverse a seconda del contesto: microfono del laptop in test locale, mixer Universal Serial Bus (USB) o analogico in sala, loopback del browser per app live come StreamYard. Chi si prende questo flusso e lo manda al server ?
Due candidati: l’app browser con getUserMedia (la strada di realtime-transcription-fastrtc), oppure uno script Python standalone lanciato dal computer dell’audio.
| Criterio | Nel browser | Script Python standalone |
|---|---|---|
| Device di sistema (mixer) | limitato | pieno accesso |
| Dipendenza da browser | sì | no |
| Testabilità | media | alta |
Scelta: Python standalone con sounddevice. In conferenza l’audio non viene dal microfono del laptop dello speaker, ma da un mixer di sala o da un microfono dedicato collegato via USB. Le Web Audio API del browser non espongono sink virtuali e mixer USB come device separati. Invece uno script Python con sounddevice accede a tutti i device che il sistema operativo espone, loopback e mixer inclusi.
Protocollo tra client audio e server
realtime-transcription-fastrtc usava Web Real-Time Communication (WebRTC); video-to-text invece WebSocket (WS). Quale ha senso qui ?
| Criterio | WebRTC | WS |
|---|---|---|
| Bidirezionalità | richiesta | non serve |
| Setup di rete | Network Address Translation (NAT), Traversal Using Relays around NAT (TURN), Interactive Connectivity Establishment (ICE) | niente |
| Affidabilità | dipende dal path | connessione persistente |
| Complessità | alta | bassa |
Scelta: WS. Il client audio manda, il server riceve. Bidirezionalità non serve, quindi WebRTC è overkill. Persistenza invece sì: il talk dura decine di minuti, l’audio va a chunk ogni 100ms, e sul server la stessa pipe mantiene aperto anche lo stream Amazon Transcribe per tutta la sessione. WS copre entrambe le cose senza i layer di WebRTC.
Canale transcript tra server e display
realtime-transcription-fastrtc usava Server-Sent Events (SSE); video-to-text WS. Quale qui ?
| Criterio | SSE | WS |
|---|---|---|
| Adatto al caso | sì | sì |
| Tecnologia già in uso | no | sì (per l’audio) |
| Codice duplicato | un secondo handler | lo stesso stack |
Scelta: WS. SSE basterebbe tecnicamente (è unidirezionale server -> client, adatto al transcript). Ma WS è già in casa per il canale audio: tenere una sola tecnologia significa un solo stack di handler server-side e una sola libreria client-side, invece di due.
Partial results vs final
Amazon Transcribe manda sia i partial (testo che cambia finché il segmento non è stabile) sia i final (stabili). Per confrontare le due modalità di delivery sul campo, il display le supporta entrambe via flag ?partial=true|false: si sceglie a runtime, non a build.
| Criterio | Partial on di default | Partial off di default |
|---|---|---|
| Leggibilità sul monitor | bassa (testo che cambia) | alta |
| Percezione latenza | buona | media |
Scelta: off di default. Un monitor dedicato con testo che si scrive, si cancella e si riscrive è sgradevole da guardare. I partial si attivano via ?partial=true sul display se in una sala specifica il ritardo dei final dovesse dare fastidio.
Lingua: zero restart tra talk
Amazon Transcribe vuole la lingua al momento di aprire lo stream (language_code="it-IT" o "en-US"). Alla PyCon le sale hanno talk consecutivi in lingue diverse: italiano, inglese. Due strade: lingua come configurazione globale del server, oppure parametro per ogni connessione del client audio.
| Criterio | Globale nel server | Parametro per sala |
|---|---|---|
| Cambio lingua tra talk | restart server | zero restart |
| Scalabilità a più sale in parallelo | tutte stessa lingua | ogni sala la sua |
Scelta: parametro per sala. Con la versione globale servirebbe restart a ogni cambio lingua (o un proxy che discrimina per path, complicando). Con parametro per sala, il server resta su per tutta la giornata e il client audio si riapre al talk successivo con la lingua giusta (?lang=it-IT o ?lang=en-US). E vale anche con più sale in parallelo: ogni sala ha la sua lingua, indipendente dalle altre.
Concretamente: ogni connessione WS è un handler indipendente su FastAPI, e ognuna apre il suo stream Amazon Transcribe con la sua lingua. Non c’è stato condiviso tra stream diversi, quindi la lingua di una sala non può influire su un’altra.
Display: app dinamica o HTML statico ?
In questo caso, il display è quello che gli spettatori guardano: un monitor dedicato con il testo che scorre man mano che arriva. Deve aggiornarsi in tempo reale ricevendo messaggi dal server, ma non fa altro: niente form, niente interazione.
Due strade: un’app dinamica (React, Vue o simili, con build e state management), oppure una pagina HTML statica con un po’ di JS che apre una WS e appende testo.
| Criterio | App dinamica | HTML statico + JS |
|---|---|---|
| Stato lato client | possibile | solo via WS |
| Deploy | richiede build | file servito dal server |
Riuso da realtime-transcription-fastrtc |
no | sì (CSS + JS) |
Scelta: HTML statico. Non serve stato lato client: il browser apre la pagina, riceve testo via WS, lo mostra. Niente build. E il CSS della modalità screen di realtime-transcription-fastrtc si riusa così com’è.
Scelte in una riga
Le scelte del realtime-transcription non nascono dal nulla: alcune sono decisioni nuove per il caso d’uso live, altre sono pezzi ripresi dai due predecessori. Eccole in riga, con la sorgente di ispirazione. Per il diagramma di sequenza con endpoint WS e flusso messaggi, vedi il README del repo.
| Scelta | Opzione vincente | Criterio | Sorgente |
|---|---|---|---|
| STT | Amazon Transcribe Streaming | niente allucinazioni | video-to-text (transcribe_service) |
| Repo | nuovo | meno debito tecnico | nuovo |
| Architettura | disaccoppiata (3 componenti) | riuso dai predecessori, flessibilità di deploy | nuovo |
| Audio client | Python standalone | accesso pieno ai device di sistema | nuovo |
| Protocollo audio | WS | connessione persistente, setup di rete minimo | nuovo |
| Canale transcript | WS | un solo stack server + client | video-to-text |
| Partial vs final | flag ?partial=true\|false |
leggibilità sul monitor | nuovo |
| Lingua | per sala | zero restart tra talk, scala a più sale | nuovo |
| Display | HTML statico | niente build, riuso di lavoro fatto | realtime-transcription-fastrtc (CSS + JS mode screen) |
Le storie che scopri solo collegando le cose
Il bello arriva quando smetti di disegnare e accendi le macchine.
Il device number su Fedora
La prima volta che ho lanciato uv run python -m audio_client --list-devices mi sono trovata davanti a una lista lunga con lo stesso hardware (le mie cuffie nel jack della docking station) che appariva più volte, con nomi simili e ID diversi. Su Linux convivono più layer audio (ALSA al kernel, JACK per l’audio pro, PipeWire come sound server moderno) e sounddevice li elenca tutti: ognuno espone lo stesso dispositivo, ognuno è un candidato sulla carta.
| Backend | ID device | Esito |
|---|---|---|
| ALSA | 1 | non funziona come ci si aspetta |
| JACK | 25 | non funziona come ci si aspetta |
| PipeWire (default di sistema) | 20 | funziona (è il routing attivo del sistema) |
Non c’è una logica che aiuti a scegliere a priori: dipende da cosa usa il sistema come routing default. Su Fedora 41 è PipeWire, quindi l’ID “giusto” era il 20. Ho provato tutti e tre prima di capirne la logica.
Regola pratica: se l’audio non arriva dove deve, prova tutti i candidati prima di mettere mano al codice.
Il loopback del browser
Una delle sorgenti audio da trascrivere è StreamYard, che è un’app browser: l’audio dello speaker esce dal browser verso il default sink del sistema. audio_client con sounddevice sa catturare da device di sistema (microfono, mixer USB), ma non sa leggere direttamente dall’output di un’app. Serve un ponte: un sink virtuale su cui il browser scrive e dal cui monitor audio_client legge.
Su Linux con PipeWire (o PulseAudio) il ponte si fa con module-null-sink. Si carica un sink chiamato loopback, si sposta sopra lo stream del browser, si punta audio_client al monitor del null-sink. Funziona al primo colpo, ma c’è un effetto collaterale: finché lo stream del browser è sul null-sink, io non lo sento più in cuffia. In sala non è un problema (l’audio arriva da mixer fisico, non dal browser del laptop). In sviluppo invece sì: non riesco a verificare cosa sto trascrivendo.
Ho provato tre vie: due sorde e una sana.
| Approccio | audio_client sente | Cuffie sentono | Note |
|---|---|---|---|
module-null-sink + move browser |
sì | no | setup base, muto sul laptop |
module-combine-sink con slaves |
no | sì | fallito |
module-null-sink + module-loopback come ramo parallelo |
sì | sì (+~50ms) | soluzione adottata |
La strada che funziona è module-loopback come ramo parallelo. Il null-sink loopback resta sorgente per audio_client; in più si carica un module-loopback che legge dal monitor del null-sink e scrive sul default sink. Due consumatori indipendenti sullo stesso monitor, nessuno blocca l’altro.
I ~50ms sono il buffer di module-loopback. Per la trascrizione non cambia nulla: il ramo di audio_client resta istantaneo. I 50ms sono solo quello che sento in cuffia rispetto a quello che parte dal browser.
Tutto è incapsulato in due comandi make: make loopback_redirect APP=firefox (che accetta anche MONITOR=1 per il ramo di ascolto in cuffia) e make loopback_clean che rimette a posto.
Scelta pratica: default MONITOR=0. In conferenza l’audio viene dal mixer, non dal laptop, quindi sentirlo in locale non serve. MONITOR=1 è un lusso da sviluppo.
Quanto hardware serve ?
Non ho ancora benchmarkato il sistema su hardware specifico, quindi mi baso su dimensioni tipiche di applicazioni Python simili. Meglio sovradimensionare rispetto a scegliere il minimo “a pelo”: su un deploy reale vuoi margine, non cadere al primo picco.
| Componente | RAM/CPU | Esempio consigliato | Note |
|---|---|---|---|
| Client audio | ~50-100MB | Pi 4 2GB con mic USB | Pi 3 in teoria basta ma tirato |
| Server | ~100-200MB base + ~30-50MB per sala | EC2 t4g.small (2GB, ARM) o Pi 4 4-8GB | Pi 4 regge 1-2 sale; EC2 per di più |
| Client display | ~200-300MB per Chromium | Pi 4 4GB | Pi 4 2GB in teoria basta ma tirato |
Tre scenari di deploy:
| Scenario | Device consigliato | Quando e perché |
|---|---|---|
| Tutti separati | Pi 4 2GB (audio) + EC2 t4g.small (server) + Pi 4 4GB (display) | Conferenza multi-sala; server in cloud per condivisione |
| Tutti insieme | Un laptop 8GB, oppure Pi 4 8GB con mic USB | Sviluppo, demo locale |
| Audio + server insieme, display separato | Pi 4 8GB (audio+server) + Pi 4 4GB (display) | Una sola sala, zero cloud; il Pi con audio ospita anche il server |
Per una sala, due Pi bastano. Con il Pi 5 (server) puoi spingerti a 2-3 sale, oltre conviene EC2. EC2 o un laptop più potente sono upgrade naturali ovunque, se vuoi più margine.
C’è altro da aggiungere ?
Quello che c’è oggi è quanto basta per una sala, con un computer qualsiasi connesso in rete. Ma il disegno regge anche oltre, quando vale la pena.
Più sale, stesso setup
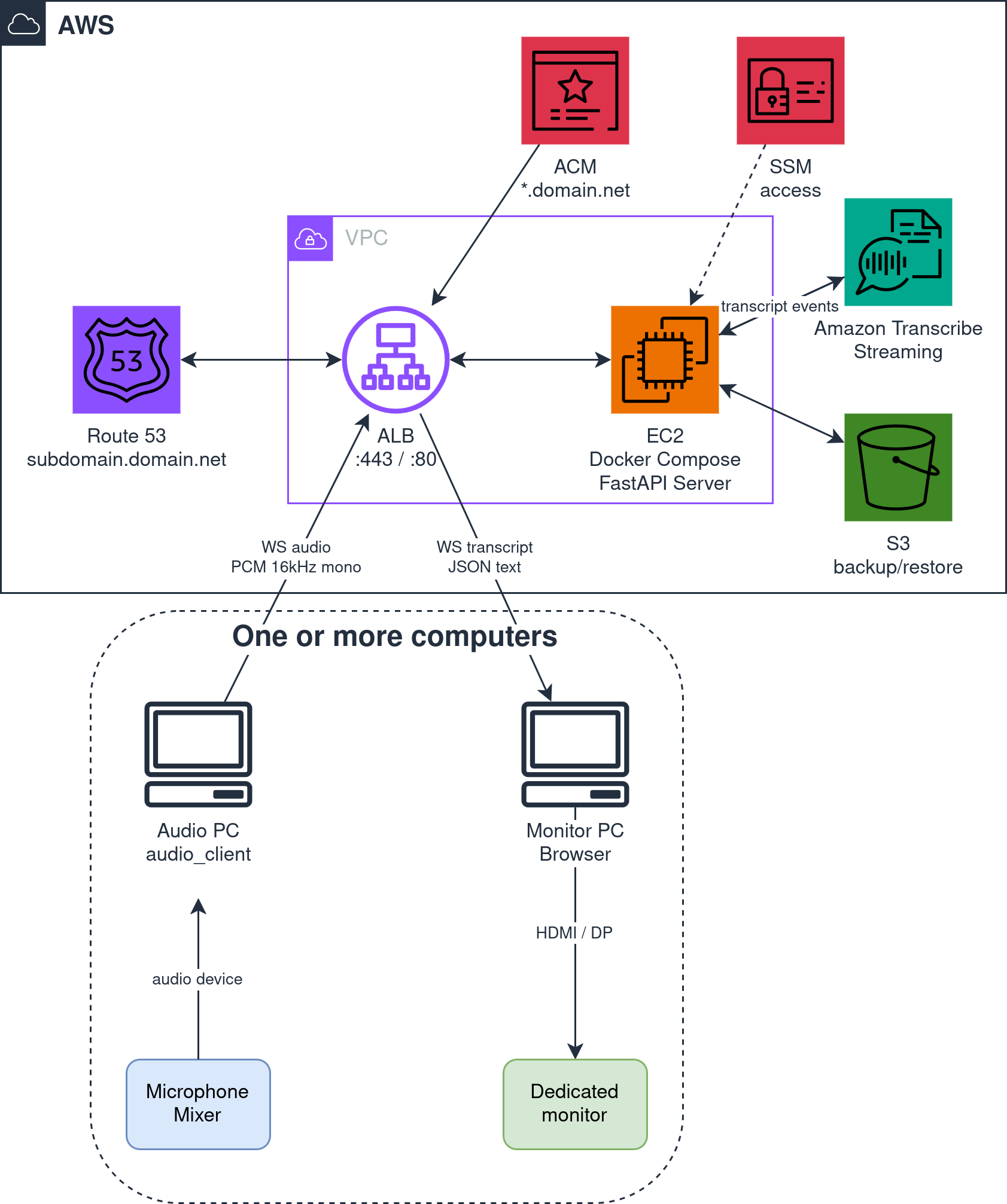
Se servono tante sale in parallelo, l’infrastruttura si può gestire con aws-docker-host, che tira su un’istanza Elastic Compute Cloud (EC2) con Docker pronto all’uso. Il server realtime-transcription nasce già con docker compose e l’immagine d’apertura descrive proprio questo scenario.
Quando una EC2 non basta: ECS Fargate
Se le sale sono molte e il carico cambia, una singola EC2 statica sta stretta. Fargate (parte di Elastic Container Service, ECS) tira su task on-demand e li spegne quando serve. Ma la trascrizione live vive su WS long-lived, e dalla documentazione AWS ci sono alcuni punti da configurare con cura (non li ho testati sul progetto):
- Sticky sessions: una connessione WS di un’ora deve restare sullo stesso task Fargate. L’Application Load Balancer (ALB) supporta WS, ma la sessione deve essere instradata con affinità. Niente round-robin a pacchetto.
- Idle timeout: il default del target group ALB è 60 secondi di inattività. Una pausa di 20 secondi tra una frase e l’altra non è inattività (il client manda silenzio ogni 100ms), ma vale la pena alzare il timeout a qualche minuto per sicurezza.
- Graceful shutdown: durante un deploy o uno scale-in, la task che chiude deve lasciare finire gli stream Transcribe aperti, non troncare a metà talk. Il container deve gestire
SIGTERMe chiudere le WS con ordine, dando al client il tempo di riconnettersi su un task diverso.
Autenticazione sui WebSocket
Oggi le WS sono aperte: chiunque conosca /ws/audio/{sala} può iniettare audio, chiunque conosca /ws/transcript/{sala} può leggere. Per un deploy in Local Area Network (LAN) o cloud privato in Virtual Private Network (VPN) va benissimo. Su internet pubblico servono almeno:
- token nel path o query (es.
?token=...), validato al connect - rate limit per Internet Protocol (IP) sul canale audio
- separazione dei permessi: chi può scrivere sulla sala X non è detto possa leggerla
Sono i requisiti minimi per esporre gli endpoint su internet pubblico.